Linear support vector machine training can be represented as a large quadratic program. We present an efficient and numerically stable algorithm for this problem using interior point methods, which requires only
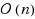 operations per iteration. Through exploiting the separability of the Hessian, we provide a unified approach, from an optimization perspective, to 1‐norm classification, 2‐norm classification, universum classification, ordinal regression and ϵ‐insensitive regression. Our approach has the added advantage of obtaining the hyperplane weights and bias directly from the solver. Numerical experiments indicate that, in contrast to existing methods, the algorithm is largely unaffected by noisy data, and they show training times for our implementation are consistent and highly competitive. We discuss the effect of using multiple correctors, and monitoring the angle of the normal to the hyperplane to determine termination.
operations per iteration. Through exploiting the separability of the Hessian, we provide a unified approach, from an optimization perspective, to 1‐norm classification, 2‐norm classification, universum classification, ordinal regression and ϵ‐insensitive regression. Our approach has the added advantage of obtaining the hyperplane weights and bias directly from the solver. Numerical experiments indicate that, in contrast to existing methods, the algorithm is largely unaffected by noisy data, and they show training times for our implementation are consistent and highly competitive. We discuss the effect of using multiple correctors, and monitoring the angle of the normal to the hyperplane to determine termination.
