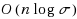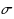| Article ID: | iaor20173250 |
| Volume: | 79 |
| Issue: | 2 |
| Start Page Number: | 291 |
| End Page Number: | 318 |
| Publication Date: | Oct 2017 |
| Journal: | Algorithmica |
| Authors: | Narisawa Kazuyuki, Hiratsuka Hideharu, Inenaga Shunsuke, Bannai Hideo, Takeda Masayuki |
| Keywords: | datamining, graphs |
This paper considers enumeration of substring equivalence classes introduced by Blumer et al. (J ACM 34(3):578–595, 1987). These equivalence classes were originally proposed to define a text indexing structure called compact directed acyclic word graphs (CDAWGs). These equivalence classes are also useful for text analysis, since they group together redundant substrings with essentially identical occurrences. In this paper, we present how to enumerate these equivalence classes using only suffix arrays and two auxiliary arrays (rank arrays and lcp arrays), in