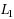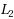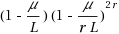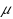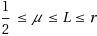| Article ID: | iaor20171755 |
| Volume: | 68 |
| Issue: | 2 |
| Start Page Number: | 307 |
| End Page Number: | 328 |
| Publication Date: | Jun 2017 |
| Journal: | Journal of Global Optimization |
| Authors: | Nguyen Duy, Ho Tu |
| Keywords: | heuristics, matrices, numerical analysis, computational analysis: parallel computers |
Nonnegative matrix factorization (NMF) is a powerful technique for dimension reduction, extracting latent factors and learning part‐based representation. For large datasets, NMF performance depends on some major issues such as fast algorithms, fully parallel distributed feasibility and limited internal memory. This research designs a fast fully parallel and distributed algorithm using limited internal memory to reach high NMF performance for large datasets. Specially, we propose a flexible accelerated algorithm for NMF with all its